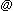 zesty.ca.
zesty.ca.
This document is maintained by Ka-Ping Yee.
He can be reached at pingzesty.ca.
Many questions can be answered by looking at the PFIF specification and the example PFIF document.
xmlns:xsi
and xsi:schemaLocation attributes for?
Here is a diagram describing the life of a PFIF record as it is created and then travels to other repositories.
.---------------------.
| 1. real-world facts |
'---------------------'
| |
entered by a human | | entered by a human
into a PFIF repository | | into a non-PFIF repository
| |
entry_date, source_date, | |
source_name, source_url | |
are set by the repository | |
v v
.-----------------------------. .------------------------------.
| 2a. original PFIF record | | 2b. original non-PFIF record |
| in record's home repository | | in record's home repository |
'-----------------------------' '------------------------------'
| |
exported as a PFIF | | parsed and converted to the PFIF
document or feed | | data model by a human or program
| |
| | source_date, source_name, source_url
| | are set by the human or program
v v
.----------------.
.--------------> | 3. PFIF record |
| '----------------'
| |
| | loaded into a PFIF repository
| |
| | entry_date is set to date/time of import
| v
| .--------------------------------------.
| | 4. clone record in a PFIF repository |
| '--------------------------------------'
| |
| | exported as a PFIF document or feed
'------------------------'
A PFIF repository can contain original records and clone records. Original records are records residing in their home repository; clone records belong to other repositories.
Each record belongs to a home repository, which is the repository where the computer record was first created (stage 2 in the above diagram). Though the record can distributed and copied into other databases, the home repository remains the authority on the record.
The person_record_id and note_record_id fields begin with a domain name and a slash. That domain name identifies the record's home repository.
The ONLY field that changes is the entry_date field, which indicates when a record entered the receiving application. No other fields change. And after a record has been stored in a repository, nothing in the record changes, not even the entry_date.
PFIF is based on a "post-only" philosophy. After a record has been stored for the first time in PFIF, it is only copied from place to place, not changed.
The source_date is the "real" date of the record: the date that the original record was created.
The entry_date is the date that this particular copy of the record was stored. The entry_date should be automatically filled in by the receiving repository; there is no need for anyone ever to manually enter an entry_date when entering data.
All the clones of a record have the same source_date as the original record. All the clones of a record will probably have different values of entry_date.
These two fields apply to both person and note records.
(The date fields labelled "Entry Date" and "Note Entry Date" on the Katrina People Finder Project entry form correspond to the source_date field in PFIF, not the entry_date field. The user should never need to enter the entry_date field.)
The purpose of the entry_date field is to enable incremental updates. If you want to mirror all the records from a remote PFIF repository into your own database on a daily basis, then you don't have to ask for a dump of the entire remote repository every day. You can just ask for all the records with an entry_date beyond the highest entry_date that you received last time.
Historical note: yes, these are somewhat confusing field names. If you are wondering why they were chosen, their origins have to do with the flow from 2b to 3 to 4 in the diagram above, which is where the Katrina People Finder Project originally focused its attention. In the case of humans reading data out of a non-PFIF repository and entering the data into a PFIF repository, these names make sense: the source_date is the date of the record in the non-PFIF source repository, and the entry_date is the date that the human enters the record into the PFIF repository. We retained these names for compatibility, though they make less sense when applied more generally. Just remember that source_date is the fixed creation date and entry_date is the automatically-set arrival date and you'll be fine.
These fields identify the (PFIF or non-PFIF) record in its home repository. source_name is the name of the home repository; source_date is the date that the record was created in the home repository; source_url is the URL to the record in the home repository.
These fields are set the first time the record is converted to PFIF, and never changed after that.
Always start with the PFIF XML document format. Your application will need to support this format in any case. If you are writing a program to format the PFIF XML directly, keep in mind that you will need to replace "&" with "&" and "<" with "<" in field values.
Embed that PFIF in an Atom feed only if you need to be compatible with an Atom feed reader. Or embed the PFIF in an RSS feed only if you need to be compatible with an RSS feed reader. The specifications of the Atom and RSS feed formats are only for compatibility with other syndication software, so that PFIF data can flow through existing syndication channels.
For all other purposes, stay with PFIF XML. Unless you are depending on other Atom or RSS software to transmit your PFIF, there is no reason to do the extra work of embedding in Atom or RSS.
PFIF-aware applications should scan the input document
for all pfif:person elements
and ignore everything else.
This will work for all three forms of input.
If you are using an XML parsing library,
ask your XML parsing library to retrieve
all the pfif:person elements in the document.
If you are using regular expressions or string matching,
search for the string "<pfif:person"
to find the start of each person element,
and search from the start of each person element
for the string "</pfif:person" to find the end of the element.
If the field is for non-changing information about the missing person, put it into the other field of the person record. The specification says:
Short fields should be on a single line with the field name, a colon, and the field value. Long fields can be given as a line with the field name and a colon, then text indented on the following lines.When a record is converted from some other form to PFIF by a machine process, the field "automated-pfif-author" should be present and should name the program that produced the PFIF. The "automated-pfif-author" field is not added when records are exported from a PFIF repository.
A description of the person in free-form text can also go here, with the field name "description". For example, a program that scrapes a record from a non-PFIF format that includes a free-form text field might produce an other field like this:
description: Dark hair, in her late thirties. Also goes by the names "Kate" or "Katie". automated-pfif-author: ScrapeMatic 0.5Field names for data fields imported from other applications should begin with the domain name and a slash. For example, if a birthdate is imported from an ICRC record, it might look like this:icrc.org/birthdate: 1976-02-26
If the field is for data that changes over time, add it as a note. There is no particular format specified for notes at the moment. Use your best judgement to format it as text; you can use the same format as the other field if you want.
Even when an application decides that multiple person records refer to the same person, it should not attempt to merge the records in place. Instead, the application should retain all the received records and present a merged display of them. Keeping the original records maintains accountability and makes it possible for the application to handle future imports of the same records from their original sources.
The Database Schema section of the specification suggests a possible way that an application based on a relational database can keep track of multiple records referring to the same person.
xmlns:xsi and
xsi:schemaLocation attributes for?These attributes are not required by the PFIF specification, but can help validation tools validate XML documents. For example, Altova's XML Spy, an XML editor and validator, recognizes these attributes and can use them to validate a PFIF document against the PFIF XML Schema.
The example PFIF document
shows how to use these attributes
to tell readers of a PFIF document
where to find the XML Schema for the document.
The xmlns:xsi attribute identifies the namespace
for an XML Schema Instance,
and the xsi:schemaLocation
maps the PFIF namespace URI to the URL for the XML Schema document.
The specification document at http://zesty.ca/pfif/1.1 includes attributes from RDDL 2.0, a proposed format for referring to an XML Schema. These attributes are present so that a program that reads a PFIF document can follow the namespace URL to http://zesty.ca/pfif/1.1, retrieve the document, and find the link to the XML Schema document at http://zesty.ca/pfif/1.1/pfif-1.1.xsd. If an XML processor supports RDDL, only the namespace has to be given, and no other attributes are needed to help locate the schema.
The RDDL attributes are properly qualified in an "rddl" namespace. The W3C validator does not know how to handle namespaces, but otherwise the specification document is valid XHTML 1.0 Strict.