Is that like Connect Four?
1. Tuples
The tuple is another type of collection
that's very much like a list.
Tuples are written much like lists, but using parentheses
instead of square brackets.
An empty tuple is written ().
A tuple with just one element is written with a comma
after the element.
So (1,) is a one-element tuple;
the comma distinguishes it from (1),
which is just the number 1.
Tuples are also sequences,
and they can be indexed and sliced just like lists.
>>> (1, 4, 7, 6, 8) (1, 4, 7, 6, 8) >>> t = (1, 4, 7, 6, 8) >>> len(t) 5 >>> t[3] 6 >>> t[:2] (1, 4) >>>
However, you cannot assign to an element of a tuple.
>>> t[3] = 5
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: object doesn't support item assignment
>>>
And tuples do not have methods that modify them, like lists do.
>>> t.append(5)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
AttributeError: 'tuple' object has no attribute 'append'
>>>
That may seem strange. Why bother to have another type of sequence that is strictly less capable than a list?
Well, it turns out that sometimes inabilities can be as useful as abilities. Perhaps you have encountered this principle in other situations. The difference between lists and tuples is that lists are mutable and tuples are immutable.
2. Mutation
A mutable object is an object whose contents can be changed. The two mutable types you've met so far are lists and dictionaries. When you pass a mutable object into a function, the function can change the object's contents too.
>>> a = [1, 2, 3] >>> a.append(4) >>> a [1, 2, 3, 4] >>> def spam(x): ... x.append(5) ... >>> a [1, 2, 3, 4] >>> spam(a) >>> a [1, 2, 3, 4, 5] >>> def edit(x): ... x[2] = 'fweee!' ... >>> a [1, 2, 3, 4, 5] >>> edit(a) >>> a [1, 2, 'fweee!', 4, 5] >>>
All the other types you've seen so far (integers, floats,
strings, and tuples) are immutable: their contents cannot be changed.
Keep in mind that's not the same as
changing the value of a variable.
Of course, you can always reassign a variable to something else.
If x contains 3, you can compute x + 1
to get a new number, 4, and assign that to x.
But that doesn't change the value of 3.
>>> a = 3 >>> b = a >>> b = b + 1 >>> a 3 >>> b 4 >>> a = "foo" >>> b = a >>> b = b + 'f' >>> a 'foo' >>> b 'foof' >>>
Now, you could do the same thing with a tuple or a list:
>>> a = (1, 2, 3) >>> b = a >>> b = b + (4,) >>> a (1, 2, 3) >>> b (1, 2, 3, 4) >>> >>> a = [1, 2, 3] >>> b = a >>> b = b + [4] >>> a [1, 2, 3] >>> b [1, 2, 3, 4] >>>
But, you can also append a 4 to the end of a list using a method:
>>> a = [1, 2, 3] >>> b = a >>> b.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4] >>>
This last case makes it clear that a
and b refer to the same list.
Calling a.append(4) tells the
list to incorporate 4 as a new element.
Saying a = a + [4] adds two lists together,
resulting in a new list, which is then reassigned to a.
Every time you use square brackets to describe a list,
that creates a new list object.
And when you add two lists together,
that also creates a new list object.
These figures compare the two cases:
no mutation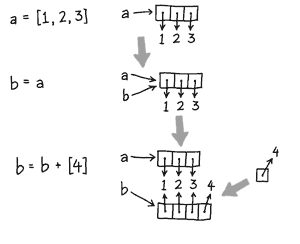 |
mutation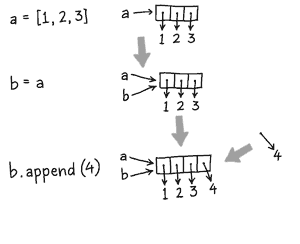 |
Another way to append 4 to the list in b
without affecting other aliases to b
is to make a copy of the list first.
Whenever you slice a list, you get a new list object.
You can get a copy of the entire list by slicing all the way
from beginning to end, as in a[:] (remember
that when you don't specify the starting or ending
index for a slice, the slice extends to the beginning or end).
The tuple doesn't provide the option to append() at all.
Once a tuple has been assigned to a,
the only way to change the value of a
is to reassign it.
So using a tuple can have an advantage over a list, depending on your purpose: if you pass it into a function, you know for sure that its contents cannot be changed. The tuple you were holding on to is guaranteed to have the same elements after the function is finished.
However, note that the elements themselves may still be mutable. If this is the case, the overall value of a tuple may change, even though tuple still refers to the same elements.
>>> a = (1, 2, [3]) >>> a (1, 2, [3]) >>> a[2].append(4) >>> a (1, 2, [3, 4]) >>>
Here's a quick digression about operators:
like C and other languages, Python has assignment operators
that combine a simple operation and reassignment.
So, for example, x += 1 increments x by 1.
In general, a += b is like a = a + b,
a *= b is like a = a * b, and so on,
except:
- The left side is only evaluated once.
For example,
dict[f()] += 1only callsf()once, unlikedict[f()] = dict[f()] + 1. - Lists mutate in-place.
So if
xrefers to[1, 2],x += [3]has the mutating effect ofx.append(3), rather than the non-mutating effect ofx = x + [3].
3. Equality and Identity
Earlier we talked about modules and functions having namespaces. A namespace is a set of names where each name refers to an object. These references are represented by the arrows in the diagrams above.
After we assign a = b as in the preceding example,
a and b refer to the same object
(they are two pointers to the same thing).
This is called aliasing.
Thereafter (as long as neither variable is reassigned),
anything we do with a will have an effect visible
in b, and vice versa.
In fact,
the two names are interchangeable;
the program would be entirely unaffected
if we replace one with the other
(again, as long as neither one is reassigned).
Have a look at this.
>>> a = [1, 2, 3] >>> b = [1, 2, 3] >>> c = a >>> >>> a [1, 2, 3] >>> b [1, 2, 3] >>> c [1, 2, 3] >>> a == b 1 >>> a == c 1 >>>
Try to predict the answers to the following questions before you test them to see if you're right.
All right. Now suppose we do a.append(4) at this point.
Q1.
What will happen to the values of
a, b, and c?
What will a == b evaluate to?
How about a == c?
Then suppose we do a = a + b.
Q2.
What are the new values of
a, b, and c?
What will a == b evaluate to?
How about a == c?
What has happened is that after
a = [1, 2, 3] and then
b = [1, 2, 3],
a and b have equal values
but different identities.
After c = a,
a and c have the same identity.
The == operator tells you if two things have equal values.
To find out if two things have the same identity,
there is a special operator called is
(and its counterpart, is not).
>>> a = [1, 2, 3] >>> b = [1, 2, 3] >>> c = a >>> a == b 1 >>> a is b 0 >>> a is c 1 >>> a is not c 0 >>>
This operator isn't used all that often,
but it's good to know what it means.
(Often people like to write
if x is None
when testing against None
because it's a little nicer to read than
if x == None.)
Just for kicks, there's also a built-in function called id()
that will yield a number representing the identity of any object.
Checking a is b is
the same as checking id(a) == id(b).
But the id() function is hardly ever used for anything.
Q3.
Try setting x = [1, 2]
and then y = [x] * 5.
What's the value of y?
What happens to y
if you do x.append(3)? Why?
Everything in Python is an object – even simple things like numbers are objects. But for immutable types that don't contain references to other things, like numbers and strings, object identity doesn't matter. For mutable types (like lists or files) or objects containing references to other objects (like tuples, dictionaries, or modules), the identity may make a difference.
If any of this is unclear to you, make sure you ask me about it.
4. Hashing and Comparison
Have you ever tried to use a list as a key in a dictionary?
>>> d = {} >>> key = [2, 3] >>> d[key] = 1 Traceback (most recent call last): File "<stdin>", line 1, in ? TypeError: list objects are unhashable >>>
That's a pretty strange error message. What's this about unhashable?
To understand what this means,
you have to know a little about how dictionaries work.
A Python dictionary is implemented as a hash table
(ask me if you don't know what this is)
so that keys can be looked up quickly.
When you look for an item in a sequence
with an expression like x in s,
Python compares x to every item in s.
Looking for a key in a dictionary
with k in d
or d[k]
is much faster,
since we compute the hash of the key,
and then just look for the hash in the dictionary's hash table.
Lists do not support hashing,
because they can mutate.
Suppose you set k = [2, 3] and used k
as a key in a dictionary d.
Imagine what happens if you do k.append(4).
It wouldn't make sense for the dictionary
to say "yes" to [2, 3] in k any more,
since there is no key equal to [2, 3].
But in order for the dictionary to know
that [2, 3, 4] in k is now true,
the contents of the dictionary's hash table would have to be reorganized
every time any key was mutated.
That would be tedious and also potentially confusing.
Consequently, lists aren't allowed to be keys. But tuples are fine.
>>> d = {} >>> key = (2, 3) >>> d[key] = 1 >>> d {(2, 3): 1} >>>
You can easily convert any sequence to a list or a tuple
by calling list() or tuple(),
in the same spirit as other kinds of type conversions.
When you compare two lists, tuples, or dictionaries, you get the same effect as if you had compared each of the elements in turn.
>>> d = {} >>> d = {2: 3} >>> d['a'] = 5 >>> d {'a': 5, 2: 3} >>> e = {'a': 5} >>> e[2] = 3 >>> e {'a': 5, 2: 3} >>> d == e 1 >>> d is e 0 >>>
Q4.
Are [1, 2] and (1, 2)
considered equivalent?
5. Packing and Unpacking
As shorthand, you can leave the parentheses off when writing a non-empty tuple.
>>> 1 1 >>> 1, (1,) >>> 1,2 (1, 2) >>>
The usual way to return more than one value from a function is to use commas, thus packing the results into a tuple.
>>> def firstlast(s): ... return s[0], s[-1] ... >>> firstlast('blargh') ('b', 'h') >>>
You can assign to more than one variable at once using a similar syntax on the left side of an assignment. The sequence on the right side is unpacked into the variables.
>>> a, b = 1, 2 >>> a 1 >>> b 2 >>>
You can even describe nested tuples on the left side of the assignment this way, and the appropriate parts of the structure will be matched up on both sides. It doesn't matter whether there are parentheses around the entire left side, and it doesn't matter what kind of sequence is on the right side (tuple, list, or string). However, keep in mind that the left side doesn't construct a tuple; it merely describes a shape. You will get an error if the shapes don't match.
>>> a, (b, c), d = [3, (4, (5, 6)), 7] >>> a 3 >>> b 4 >>> c (5, 6) >>> d 7 >>> a, b = 3 Traceback (most recent call last): File "<stdin>", line 1, in ? TypeError: unpack non-sequence >>> a, b = [3, 4, 5] Traceback (most recent call last): File "<stdin>", line 1, in ? ValueError: unpack list of wrong size >>>
Finally, you can also get the effect of more than one assignment by chaining equals signs together.
>>> x = y = z = 0 >>> x, y, z (0, 0, 0) >>> a, (b, c) = (d, e), f = [(3, 4), [5, 6]] >>> a (3, 4) >>> b 5 >>> c 6 >>> d 3 >>> e 4 >>> f [5, 6] >>>
The same kind of unpacking takes place when you call a function.
>>> def poo(w, ((x, y), z)): ... print w, x, y, z ... >>> poo(3, ((4, 5), (6, 7))) 3 4 5 (6, 7) >>> poo(3, ['ab', 8]) 3 a b 8 >>>
Items are also unpacked in for loops.
>>> sentence = 'Pack my box with five dozen liquor jugs.' >>> results = [] >>> for word in sentence.split(): ... results.append(firstlast(word)) ... >>> results [('P', 'k'), ('m', 'y'), ('b', 'x'), ('w', 'h'), ('f', 'e'), ('d', 'n'), ('l', 'r'), ('j', '.')] >>> for first, last in results: ... print first + '-' + last, ... P-k m-y b-x w-h f-e d-n l-r j-.
One of the most common ways this is used is with
the items() method on dictionaries,
which returns a list of the (key, value) pairs
in the dictionary.
This lets you conveniently iterate over the keys and values
at the same time.
Q5.
Write a function invert(dict)
that takes a dictionary and constructs the inverse dictionary
(that is, whenever the given dictionary maps key x to value y,
the result should map key y to value x.)
Use the items() method to extract the contents.
You can assume that no two keys in the given dictionary
map to the same value, and that all the values are hashable.
When you wrote the count()
function in the last lab,
you used a dictionary as a multiset
(a set that can contain the same value more than once).
The following question asks you to use a dictionary
as a multimap (a mapping where each key may be
associated with more than one value).
Q6. Adjust your function to handle the case where some keys do map to the same values. Your goal is to be able to use the inverted dictionary to quickly retrieve all the keys that were mapped to a given value. How do you have to change the structure of the result in order to preserve this information?
6. Variadic Functions
An additional feature of function definitions is the ability to take a variable number of arguments. You specify this by putting a star in front of an argument name as the last argument in the list. That variable will receive a tuple containing all the rest of the arguments.
>>> def total(*numbers): ... result = 0 ... for number in numbers: ... result += number ... return result ... >>> total(1) 1 >>> total(1, 3, 5) 9 >>>
The built-in functions min() and max()
can take a variable number of arguments.
If max() is given just one argument,
a sequence is expected; the largest element of the sequence is returned.
If max() is given more than one argument,
the largest argument is returned.
>>> max(1, 2) 2 >>> max([1, 4, 3]) 4 >>> max([1, 4, 3], [1, 7, 2]) [1, 7, 2] >>> max(1) Traceback (most recent call last): File "<stdin>", line 1, in ? TypeError: iteration over non-sequence >>>
Q7.
Write a definition for max()
that works just like the built-in function.
It's also possible to write functions that accept a variable number of keyword arguments, by providing a special argument at the very end (after the star-argument, if any) with two stars. That variable gets a dictionary containing all the extra keyword arguments (that is, keyword arguments that don't match other argument names). When you call a function, the keyword arguments must come after any normal arguments.
def f(a, b, c=5, d=6, *e, **f): print a, b, c, d, e, f
Q8. Given the above function, predict what will happen in each of the following cases:
>>> f(4, c=5) ? >>> f(4, 7, d=9, 8) ? >>> f(4, 7, d=9, g=2) ? >>> f(4, 7, d=6, e=8) ? >>> f(4, d=6, b=7, e=8) ? >>>
Then, test your predictions.
7. Handy Sequence Functions
There are three built-in functions that take a function
as the first argument and a sequence as the second:
map(), filter(), and reduce().
map(func, seq) applies a one-argument function
func() to each item in the sequence seq
and returns a new list containing the corresponding return values
from func(). The result is always a list, regardless
of the kind of sequence given.
>>> def double(x): ... return x * 2 ... >>> map(double, (2, 4, 3, 5, 6, 7)) [4, 8, 6, 10, 12, 14] >>>
filter(func, seq) applies a one-argument function
func() to each item in the sequence seq
and returns a new list containing items from the original sequence
for which func() returned a true value. The result
is the same type as the original sequence.
>>> def small(x): ... return x < 10 ... >>> filter(small, (2, 14, 9, 15, 11, 6)) (2, 9, 6) >>> >>> def vowel(x): ... return x in 'aeiouAEIOU' ... >>> filter(vowel, 'hyper-pythonic') 'eoi' >>>
reduce(func, seq) uses a two-argument function
func() to combine all the elements of the sequence
seq. It takes the first and second elements and
calls func() on them, then takes the result and the
third element and
calls func() on them,
then calls func() on that result and
the fourth element,
and so on until the entire sequence has been consumed.
>>> def add(a, b): ... return a + b ... >>> reduce(add, [3, 8, 6, 4, 3, 2, 7, 2]) 35 >>>
Q9.
What would reduce(diddle, 'abcd') produce,
if diddle(x, y) is defined as x + y + x?
Figure out the answer before you try it.
8. List Comprehensions
Python offers another way to generate lists based on other lists
that may be easier to understand in some situations.
This construct always begins with a square bracket, an expression,
and the keyword for. Here's an example:
>>> [x*x for x in range(5)]
[0, 1, 4, 9, 16]
>>>
The effect is exactly the same as if the for
loop had appended the value of the expression to a new list:
>>> result = [] >>> for x in range(5): ... result.append(x*x) ... >>> result [0, 1, 4, 9, 16] >>>
The for clause can also be followed
by any number of if clauses or other for clauses.
Again, the effect is just the same as if the if conditions
and for loops were nested in the order written.
>>> [c for c in 'quick brown fox' if c > 'm'] ['q', 'u', 'r', 'o', 'w', 'n', 'o', 'x'] >>> [x*y for x in range(2, 5) for y in range(1, 6)] [2, 4, 6, 8, 10, 3, 6, 9, 12, 15, 4, 8, 12, 16, 20] >>>
There is still a little controversy about whether
list comprehensions are good,
since they yield an extra way to do something that can already be done
with a for loop or with map().
I've introduced them here so you'll recognize them
when you encounter them.
For simple cases, like these examples,
they can be significantly more concise
than the equivalent for loop.
But i don't recommend using them for anything too complicated
(perhaps two clauses is a reasonable limit).
Q10.
Rewrite the statement
result = [c for c in 'quick brown fox' if c > 'm']
without using list comprehensions,
first using map() and filter(),
then without using map() or filter().
9. Slice Assignment
This is just an extra feature of lists that's quite handy sometimes. You can assign a list to any slice of a list, which will mutate the contents of the list to replace the indicated slice. You can use this to do many things, including inserting elements, removing elements, or chopping off the end of a list.
>>> x = [2, 5, 6, 9] >>> x[2:3] [6] >>> x[2:3] = [1, 2, 3] >>> x [2, 5, 1, 2, 3, 9] >>> x[1:1] [] >>> x[1:1] = [0] >>> x [2, 0, 5, 1, 2, 3, 9] >>> x[-3:] [2, 3, 9] >>> x[-3:] = [] >>> x [2, 0, 5, 1] >>> x[:] = [1, 1] >>> x [1, 1] >>>
Throughout all the operations in the above example,
the identity of x is unchanged;
x is never reassigned.
We're just changing around the contents of the list
to which x refers.
All right! Onward to the fourth assignment.
If you have any questions about these exercises or the
assignment, feel free to send me e-mail at
bc zesty
zesty ca.
ca.